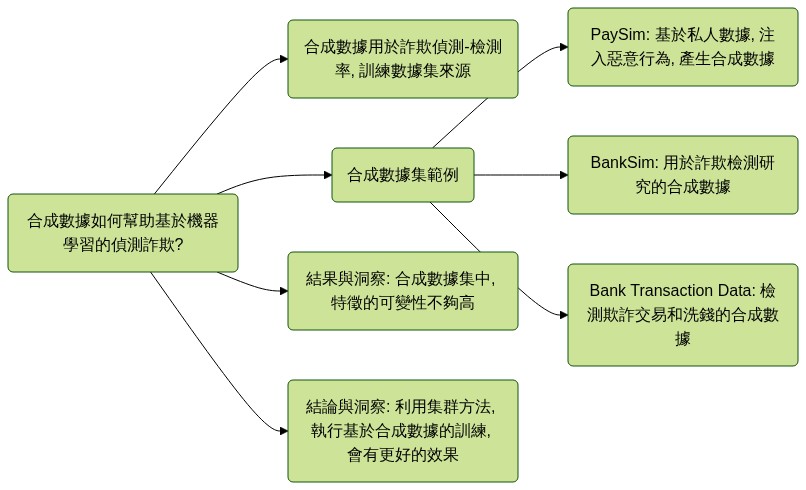
合成數據如何幫助基於機器學習的偵測詐欺?

紫式晦澀每日一篇文章第5天
前言
-
今天是2022年第3天, 第一週的第一個週一!今天來思考「合成數據(Synthetic Data)」是如何在金融科技領域中,幫助「詐欺偵測(Fraud Detection)」的任務.
-
今天的素材主要是從文章Follow the Trail: Machine Learning for Fraud Detection in Fintech Applications 節選提到合成數據的相關段落 .
合成數據用於詐欺偵測-檢測率, 訓練數據集來源
-
合成數據對詐欺偵測的效果: 本文章實驗了ML方法對欺詐檢測的貢獻, 分別利用真實數據集與「合成數據集」來訓練. 此文章討論了各種方法在「檢測率」的有效性. 此外, 分析了所選特徵對其性能的影響.
-
詐欺偵測的訓練數據集-Kaggle, ML Repository, Simulator:
- A. 金融科技的詐欺檢測, 缺乏公開可用的測試數據.
- B. 來源一: Kaggle數據集 (括信用卡數據集[9]、銀行交易數據[10]和區塊鏈歷史數據[11]).
- C. 來源二: 已知的、稍舊的合成數據集可以在UC Irvine ML Repository中找到(例如,UC Irvine[12])
- D. 來源三:模擬器(Simulator) BankSim[13]和PaySim[14]等模擬器被應用於解決這個問題。前者代表了一個基於代理的銀行支付模擬器,而後者則通過生成客戶和執行交易來模擬移動交易。
合成數據集範例
PaySim: 基於私人數據, 注入惡意行為, 產生合成數據
- PaySim的模擬器:
- A. 在4.2.2節中,將介紹一個使用名為PaySim的模擬器生成的合成數據集(PaySim數據集在下文中)。
- B. PaySim使用私人數據集的匯總數據,生成一個類似於交易正常運行的合成數據集,並注入惡意行為,以便日後評估欺詐檢測方法的性能。
- C. 這是通過在一個非洲國家的真實交易樣本基礎上模擬移動支付交易來實現的。原始數據是由一家跨國移動金融服務提供商提供的[104]。
- D. 在這個特定的數據集中,代理商的欺詐行為旨在通過控制或客戶的賬戶來獲利,並試圖通過轉移到另一個賬戶來清空資金,然後從系統中套現。
- E. 數據集詳情見表5。 Table 5. Synthetic Financial Datasets for Fraud Detection dataset overview.
Dataset name Synthetic Financial Datasets for Fraud Detection Domain Financial Transactions Url https://www.kaggle.com/ntnu-testimon/paysim1 Year (accessed on 30 November 2020) Type 2015 Subset Synthetic data Annotated PS_20174392719_1491204439457_log.csv Unbalanced Yes No. of entries Yes Contamination rate 6,362,620 Time duration 0.129% No. of features 1 month List of features 11 step, type, amount, name0rig, oldbalance0rg,
- 定義PaySim: PaySim.
- A. 一個移動貨幣支付模擬器 移動貨幣支付模擬案例研究是基於一個真實的公司,該公司開發了一個移動貨幣實施方案,為手機用戶提供了使用手機作為一種電子錢包在他們之間轉移資金的能力。
- B.「任務」是開發一種能夠檢測出表明欺詐的可疑活動的方法。
- C. 不幸的是,在我們研究的最初階段,這項服務只在演示模式下運行。這使我們無法收集任何可用於分析可能的檢測方法的數據。
- D. PaySim的開發包括兩個階段。
- D.a 在第一階段,我們模擬並實現了一個MABS,它使用了真實的移動支付服務的模式,並根據對真實系統開始運行時可能出現的情況的預測,生成了合成數據。
- D.b在第二階段,我們獲得了該系統的財務交易日誌,並開發了一個新版本的模擬器,該模擬器使用匯總的交易數據來生成更類似於原始來源的財務信息。
- E. Keywords [en]: multi-agent based simulation, fraud detection, retail fraud, synthetic data http://bth.diva-portal.org/smash/get/diva2:1085629/FULLTEXT03.pdf .
BankSim: 用於詐欺檢測研究的合成數據
- BankSim:
- A. 小節4.2.3 介紹的數據集是使用BankSim創建的,這是一個基於代理的銀行支付模擬器,基於西班牙一家銀行提供的匯總交易數據樣本。
- B. 目標: 生成可用於欺詐檢測研究的合成數據。
- C. 這個數據集結合了正常的支付和已知的欺詐特徵,不包含任何個人信息或任何其他交易的披露。
- D. 數據集的詳情見表6。
Dataset name Synthetic data from a financial payment system Domain Financial Transactions Url https://www.kaggle.com/ntnu-testimon/banksim1 Year (accessed on 30 November 2020) Type 2014 Subset Synthetic data Annotated bs140513_032310.csv Unbalanced Yes No. of entries Yes Contamination rate 594,643 Time duration 1.21% No. of features 6 months List of features 10 Subset step, customer, age, gender, zipcode0ri, Annotated merchant, zipMerchant, category, amount, fraud Unbalanced bsNET140513_032310.csv No. of entries Yes Contamination rate Yes Time duration 594,643 No. of features 1.21% List of features 6 months
Bank Transaction Data: 檢測欺詐交易和洗錢的合成數據
- Bank Transaction Data:
- A.Bank Transaction Data是一種分析工具,旨在檢測欺詐交易和洗錢。
- B. 開發人員希望建立一個工具,可以使用IFSC代碼提取銀行名稱;通過系統獲取兩個不同賬戶在同一日期的借方和貸方的相同數量的交易以及匹配的敘述;並在敘述的基礎上對類似交易進行分類。
- C. 數據集的細節見表7。
Dataset name Bank Transaction Data Domain Financial Transactions Url https://www.kaggle.com/apoorvwatsky/bank- Year transaction-data (accessed on 30 November 2020) Type 2017 Subset Synthetic data Annotated bank.xlsx Unbalanced No No. of entries n//a Contamination rate 116,201 Time duration n//a No. of features 7 months 8 List of features Account No., Date, Transaction Details, Cheque No. , Value Date, Withdrawal Amount, Deposit
結果與洞察: 合成數據集中, 特徵的可變性不夠高
Variability of features in a synthetically created dataset might not be on a high enough level.
- 合成數據集中, 特徵的可變性不夠高:
- 圖15中給出了被測試的集合方法的ROC曲線比較。
- 基於tpr和tnr的比較分析表明,對於一個給定的數據集,AdaBoost在測試方法中表現最好。
- 同時,可以注意到這三種測試方法的靈敏度和特異性都很高,幾乎為1,這表明合成的數據集中特徵的可變性可能還不夠高(variability of features in a synthetically created dataset might not be on a high enough level)。
- 還應該注意的是,在這個特定的數據集上,集合方法的表現優於離群點檢測方法。

結論與洞察: 利用集群方法, 執行基於合成數據的訓練, 會有更好的效果.
ensemble approaches significantly outperformed outlier detection methods on the two tested synthetic datasets
- 集成方法在合成數據集上表現較好
- 所進行的實驗結果證實了ML的好處。
- 首先,現有的ML算法成功地在複雜的數據集中檢測到了異常情況。
- 此外,實驗結果證實,ML方法可以通過支持增強欺詐檢測能力的方式,成功地為金融技術系統的安全做出貢獻。
- 此外,研究還發現,特徵工程和選擇會嚴重影響某些算法的性能,仔細選擇特徵可以提高整體性能並限制某些特徵的負面影響。
- 還應注意的是,集合方法對可變的特徵選擇情況保持了更穩健的性能,總體表現非常好,在大多數情況下比離群值檢測方法更好
- 集合方法在兩個測試的合成數據集(PaySim和BankSim)上的表現明顯優於離群值檢測方法 (ensemble approaches significantly outperformed outlier detection methods on the two tested synthetic datasets)
- 而在包含真實數據的測試數據集(CreditCard)上,這兩種方法的結果是相當的。
後記
-
到此我們看過了Follow the Trail: Machine Learning for Fraud Detection in Fintech Applications 文章中關於「合成數據」的段落與洞察。本文章指出(1) 公開用於訓練機器學習模型的合成數據集(PaySim 與 BankSim), 特徵的可變性可能不夠高, (2) 利用集群方法(Ensemble Method), 執行基於合成數據的訓練, 會有更好的效果.
-
這邊所謂的「合成數據」的邏輯, 似乎是加入惡意行為, 然後看使用的算法是否能夠成功抓到惡意行為. 惡意行為的「產生機制」可否用deep learning來做呢? 這樣的generative model, 生成帶有隱藏惡意行為的驗證資料(Validation dataset), 以此來審計(audit)系統中使用的機器學習算法. 這類似學校對TA做種族平等的培訓, 以避免TA在課堂上做出違反符合美國大學系統價值下認為的平等.
-
十分有趣, 之後需要多學習一些詐欺偵測的資料科學工程技術, 來進一步思考此文章給出對合成數據集的洞察. 持續精進, 共勉之!
2022.01.03. 紫蕊 於 西拉法葉, 印第安納, 美國.
評論